
案例中心
- 发布日期:2025-12-26 11:06 点击次数:191
为编造实验通讯限制带来了改进性碎裂
(映维网Nweon 2025年12月25日)理思的数字汉典呈现体验需要精准地复制一个东说念主的体魄、服装和动作。为了拿获有计划动作并将其涟漪到编造实验中,不错采选自中心(第一东说念主称)的视角,这使得无需前视录像头即可使用便携式且具有老本效益的开荒。然而,这带来了诸如紧闭和误解的体魄比例等挑战。
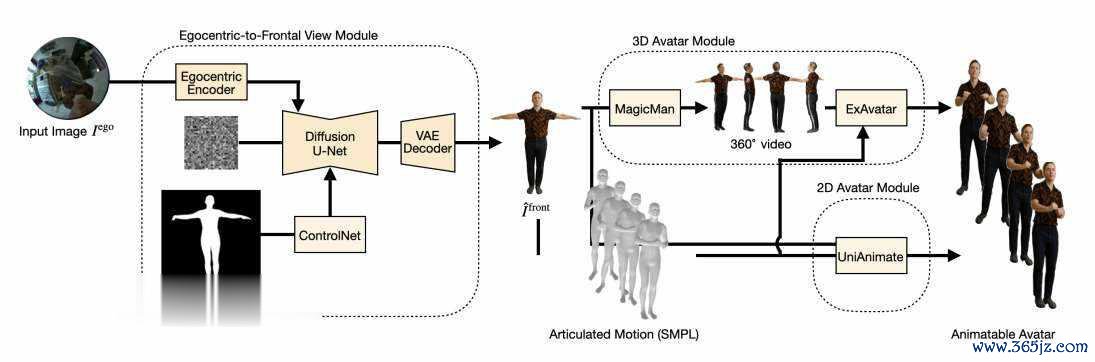
受SiTH和MagicMan等从正面图像进行360度重建的秩序的启发,索尼团队引入了一个管说念,使用ControlNet和褂讪扩散骨干从装束的从上至下图像生成传神的正面视图。团队的倡导是将单个从上至下的以自中心的图像诊疗为实验的正面暗示,并将其输入到图像-怒放模子中。这使得从最小的输入生成的化身怒放,铺平了说念路,更易于拜谒和通用的汉典呈现系统。
这项本领已矣了仅凭单个头戴录像头拍摄的俯瞰角图像,就能生成具备艰深服装纹理和齐全体魄结构的可动画数字化身,队编造实验通讯限制具有遑急真谛。

传统编造实验通讯系统需要依赖复杂的多录像头阵列或专科动捕开荒,才略创建果然的数字东说念主形象。这不仅老本腾贵,也放胆了应用的普及性。尽管频年来出现了基于单目次像头的处理有策划,但它们大多依赖于传统的正面视角,无法有用处理头戴式录像头私有的俯瞰角图像。
头戴式录像头固然老本便宜且易于集成,但其拍摄的图像存在三个中枢挑战:严重的体魄装束(下半身和背部简直不能见)、非规范的透视角度(从上往下的畸变视角),以及误解的体魄比例。这些身分使得现存的图像到化身生成秩序,如ExAvatar、AnimateAnyone等皆难以胜仗应用。
EgoAnimate的中枢创新在于将复杂的生成任务说明为两个相对独处且可优化的阶段。第一阶段专注于处理最具挑战性的视角诊疗问题,将严重装束的俯瞰图诊疗为澄莹的正面T姿势图像。第二阶段则应用现存的先进动画生成本领,基于诊疗后的正面图像创建最终的可启动化身。
这种模块化联想不仅裁减了举座任务的复杂度,还使得系统约略生动适配不同的动画生成有策划。究诘团队的倡导不是再行发明轮子,而是通过处理最枢纽的瓶颈问题——视角诊疗,来开释现存本领的后劲。
视角诊疗模块是EgoAnimate系统中最具本领创新的部分。模块基于Stable Diffusion架构,但进行了多项枢纽改良。
在编码阶段,系统采选双重编码机制。率先,输入的512×512俯瞰角图像通过冻结的VAE编码器被压缩到潜空间,酿成基础的视觉暗示。与此同期,吞并图像还通过CLIP视觉编码器索要高层语义特征。这些特征经过线性投影和空间彭胀后,通过交叉细心力机制注入到去噪U-Net中。这种联想使得模子约略领悟输入图像的语义本色,并据此推断被装束区域的外不雅。
为了确保生成的东说念主体结构准确,团队引入了ControlNet进行姿态限制。该网罗以倡导东说念主体的SMPL姿态掩码算作条款输入,将其编码为空间特征图后,胜仗添加到U-Net的残差流中。这至极于为生成历程提供了一个精准的东说念主体骨架蓝图,确保输出图像中的东说念主体比例和姿态允洽剖解学范例。
在检会战略方面,团队采选了复合亏空函数,将传统的噪点预测亏空与LPIPS感知亏空相集聚。这种组合迫使模子不仅在像素层面接近果然正面图像,更在视觉感知上保证生见遵循的合感性与天然度。消融实考评释,加入感知亏空后,生成图像的视觉质地得到权臣耕种。
在获取高质地的正面T姿态图像后,EgoAnimate提供了两种不同的动画生成旅途供接纳。
3D高斯化身旅途旨在生成可被当代游戏引擎和渲染系统胜仗使用的3D数字东说念主。有计划旅途率先使用MagicMan模子将单张正面图彭胀生成包含20个角度的多视图图像序列,其中包括RGB图像和对应的法线贴图。随后,这组图像被输入至基于3D高斯溅射的ExAvatar系统中,重建出可启动的3D化身。固然这条旅途能产出信得过的3D模子,但团队发现MagicMan生成的多视图存在微弱伪影,导致最终化身的视觉保真度有所亏空。
2D视频化身旅途则绕过复杂的3D重建历程,胜仗生成动画视频序列。究诘团队系统性地评估了多个前沿的图像到视频模子,包括MimicMotion、StableAnimator和UniAnimate。经过41名参与者的盲测评估,UniAnimate在服装一致性、怒放果然感和动画怒放度三个维度上均施展最好。尽管其生成速率相对较慢(以ExAvatar为基准1.0,UniAnimate为22.5),但输出质地的上风使其成为团队的最终接纳。
高质地的检会数据是EgoAnimate到手的枢纽。为了处理俯瞰-正视配对数据稀缺的问题,究诘团队自主构建了一个特别的数据集。
数据集中历程中,参与者佩带装有录像头的头盔来获取俯瞰角图像,同期使用外部录像头同步拿获正面视图。悉数系统无需深度传感器或多视角阵列,大大裁减了集中复杂度。通落伍间戳和体魄姿态匹配,每个正面图像与温和10张不同的俯瞰帧开发对应关系,有用引入了怒放各种性。
值得细心的是,团队使用现成的扩散模子对正面图像进行了后处理增强,改善光照条款和视觉传神度。固然这些增强图像并非严格真谛上的果然数据,但它们为模子检会提供了更澄莹的监督信号,权臣耕种了生成质地。
在定量评估中,EgoAnimate在多个策划上均施展出色。在图像生成质方位面,其在PSNR、SSIM和LPIPS三个规范策划上均优于基线模子。脱落引东说念主详确的是在服装还原准确率上的施展:在辞别短裤与长裤的任务中达到87%的准确率,在辞别T恤与毛衣的任务中达到79%的准确率,这评释了模子对语义本色的深远领悟。
更令东说念主印象深远的是模子的泛化才略。尽管检会时仅构兵过自集中的数据集,EgoAnimate在齐全未参与检会的Ego4D数据集、网罗下载的Instagram图片,以致是动态复杂的公园跑GoPro素材上,皆能到手生成合理的动画化身。这种高大的跨数据集泛化才略标明,模子学习到的是普适的视角诊疗旨趣,而非对检会数据的肤浅挂牵。
EgoAnimate本领的出现为多个限制带来了新的可能性。在编造实验外交平台中,用户不错快速创建与我方外不雅一致的数字化身,无需专科开荒即可已矣高千里浸感的互动。在汉典配合场景下,参与者约略以更天然的面貌进行疏导,传递丰富的非话语信息。
天然,究诘团队同期坦诚指出了现时本领的局限性。数据集聚东说念主体体型、肤色和服装格调的各种性仍有待耕种,这关系到本领的自制性和普适性。由于俯瞰角底下部信息严重缺失,系统主动废弃了对面部区域的建模,这在需要色彩疏导的场景中是个澄莹短板。关于长款大衣、裙摆等具有复杂几何结构的服装,模子的还原才略仍有耕种空间。
估计往时,团队接洽通过引入时序信息来处理动态服装,探索基于短视频片断的一致性生成。面部区域的复原亦然一个遑急倡导,可能通过集聚生成式先验与部分可见信息来已矣。跟着本领的进一步完善,EgoAnimate有望成为下一代编造实验通讯的基础本领,让每个东说念主皆能以最天然的面貌在数字宇宙中呈现自我。
筹论说文:EgoAnimate: Generating Human Animations from Egocentric top-down Views
总的来说,EgoAnimate代表了单视角数字东说念主生成本领的遑急跳跃。通过隐秘地集聚前沿的生成模子与模块化联想理念,它评释了从最小化、最易得的传感器输入中创建高质地动画化身的可行性。这项究诘不仅为学术社区提供了新的究诘倡导,同期为产业界开发普惠型VR/AR应用提供了实用的本透露径。
- 索尼研发基于头戴录像头的编造实验化身生成本领2025-12-26